Data acquisition and organization
The core of the data set construction is the authority and the practicality of its content. Therefore, the official exam questions, which were published via public channels for the registered architects and the tests of the registered planners, are primarily collected. The questionnaire includes a collection of actual exam questions from previous years and a selection of high -quality bogus questions in order to cover the core knowledge of professional qualification certification. The entire test set comprises 10,440 questions that are all questions with just a correct answer between four options. In addition, paper -based exam work and practice questions are asked by university, which were carefully put together by experienced teachers in order to ensure the precision and widespread recognition of the questions and answers. Since these resources are usually not publicly available online, they are not easily accessible to web crawlers and offer our data record with a clear value and depth.
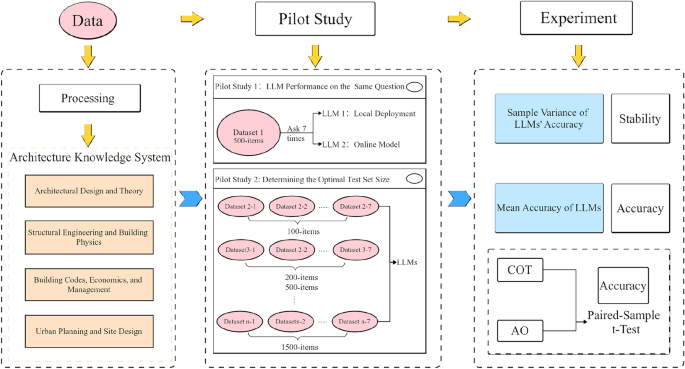
In order to ensure the scientific accuracy and completeness of the test set, the sample strategy strictly follows the distribution relationship of questions about various subjects in the entire questionnaire (Figure 5). This approach is intended to ensure that the test set completely covers and represents the entire knowledge system, which provides a precise and balanced data basis for the evaluation of the performance of LLMS.
Percentage of questions about subject in the questionbank.
Models
In order to examine the latest applications and progress of LLMS in the Chinese architectural area of knowledge, a comprehensive evaluation of 14 high-performance LEFs, which support the Chinese input, was carried out (Table 1). The selection of these models was based on their widespread use and high frequency in the Chinese domain as well as in the support of professional development and business teams. This not only ensures the authority and professionalism of the models, but also guarantees their potential for future continuous development and optimization.
Preliminary experimental results
All experiments in this article were carried out in the following configurated environment, whereby the relevant configurations and their parameters were displayed in Table 2.
Preliminary experiment ①
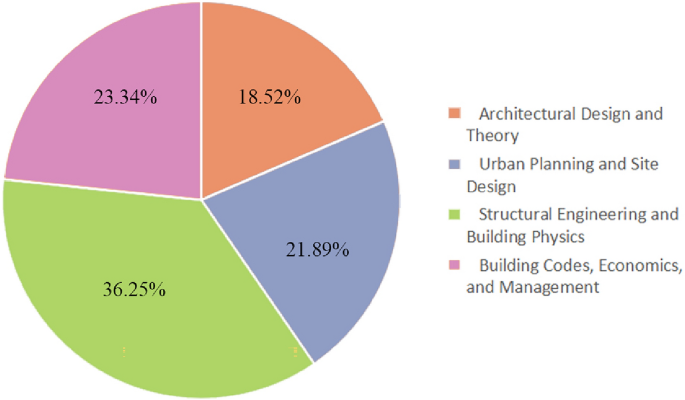
Preliminary experiment ① Selected two LLMs, QWen-14b chat and GPT-3.5 turbo, for testing. QWen-14b is a locally provided LLM, while GPT-3.5 turbo is an online LLM that represents two different provision methods of LLMS. A test set (data record 1) with a random sample of 500 questions was taken from the entire pool. Both models were asked 7 -times of the same questions, with the AO method optimizing the questionnair process process and shortening the time for the question and answer. The experimental results (Figure 6) show that the answers from QWen-14b chat for the 7 attempts were completely consistent, while GPT-3.5 turbo gave different answers. The total output of GPT-3.5 turbo was essentially stable via the 7 answers, with accuracy differences \ (\ The 0.8 \% \). There was no clear linear relationship between rounds and accuracy, which means that the accuracy of GPT-3.5 turbo during the test period did not significantly improve. The reason could be that the online model GPT-3.5 turbo uses unattended learning techniques to adapt its parameters, which leads to different outputs at different times. As a locally provided, QWen-14b chat probably uses the same environment and parameter settings every time if it leads to a relatively stable output.
Preliminary experiment ① Results output stability test results for QWen-14b chat and GPT-3.5 turbo.
Preliminary experiment ②
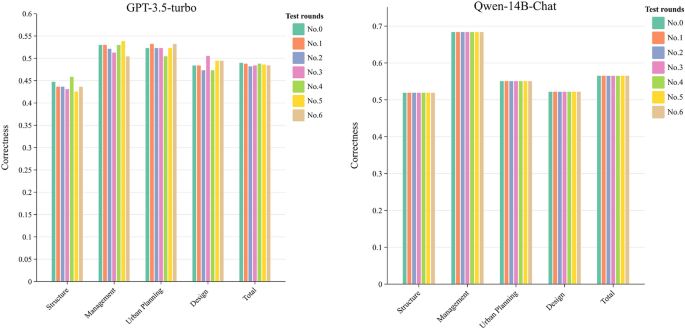
The preliminary experiment ② aimed at determining an optimal test set that is able to ensure stable efficiency without affecting the accuracy and representativity of the test results. This can rationalize the amount of questions in the test sentence to save time for subsequent experiments. In this section, we have implemented a methodically increased size of the test set, starting with 100 questions and gradually increasing the number to 200, 500, 1000 and ultimately 1500 questions to monitor the variance in the sample distribution.
Preliminary experiment ② Results-game variance of accuracy for QWen-14b chat and GPT-3.5 turbo outputs on different test set sizes.
The test results were shown in Figure 7. It was indicated that the sample variance of the accuracy of the model stabilizes and remains at a low level if the test set is approximately 875 questions. Such a finding indicated that the influence of the test set on the evaluation results of the model in the size of 875 questions is minimized, which ensures the stability and reliability of the evaluation. Therefore, the test size for all subsequent experiments is set to 875 questions.
Main experimental results
Stability assessment of LLMS
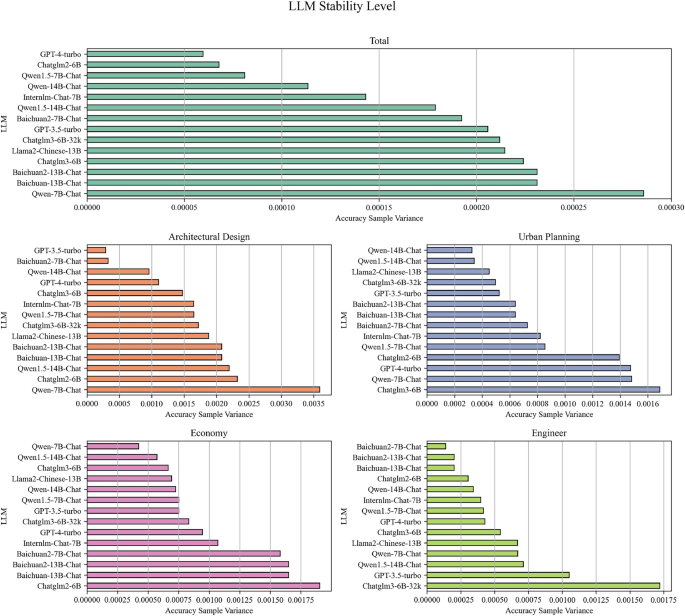
In order to evaluate the stability for LLMS, we used a correspondingly scaled test set, as determined in the previous preliminary experiments to evaluate each model. It was achieved by calculating the sample variance of the test results, which quantified the stability of the models. The size of the sample variance was correlated directly with the fluctuation in the performance of the LLM across different test sets: a larger variance showed a stronger fluctuation in the test results of the LLM, which reflected a lower stability. A lower variance implied more consistent test results, which indicates higher stability of LLM.
According to the experimental data in Figure 8, the online mode of GPT-4 turbo showed the highest overall stability with a sample variance of 0.000060. Chatglm2-6b and QWen1.5-7b chat were next in the line, which also showed praise stability with random variations of 0.000068 and 0.000081. Other models, including QWen-7b chat and Baichuan2-7b chat, also showed good stability in certain special domains.
In the diagrams, the model stability for various subjects was further delimited: In the subjects of “Design” and “Urban Planning”, the models GPT-3.5-Turbo, QWen-14b chat and Baichuan2-7b chat relatively low sample variations were pointed out to a more stable performance. In the subjects of “Management” and “Structure”, the models QWen-7b-Chat, Baichuan2-7b chat and QWEN1.5-14b chat showed lower sample variations, which meant superior stability in these disciplines.
Preliminary experiment ② Results-game variance of accuracy for QWen-14b chat and GPT-3.5 turbo outputs on different test set sizes.
Accuracy assessment of LLMS
During the process of accuracy validation for LLMs, the medium -sized accuracy rates derived from the stability assessment were used as a benchmark for the evaluation. The most recent evaluation results showed that the QWEN1.5-14b chat model was particularly excellent in terms of accuracy and exceeded the leading GPT-4 turbo. In addition, other models in the “Qwen” series showed a remarkable performance (Figure 9).
It was particularly noteworthy that in the area of building regulations, economy and management, all rated models generally had a high degree of accuracy, which indicates that LLMS already had a relatively ripe potential for application in the areas. However, the high -ranking models had not achieved the average performance in the object of the design as in other areas. Such a phenomenon was particularly outstanding for the top models. This not only shows the potential restrictions of LLMS in this area, but also provides an important reference for future model optimization and fine -tuning.
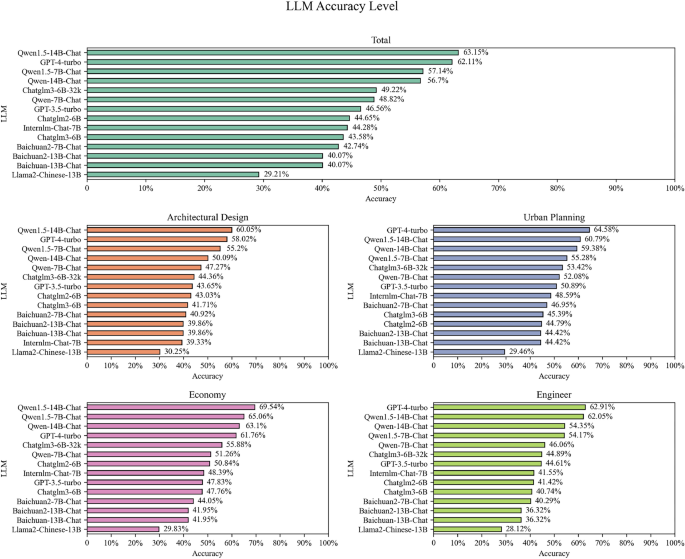
Accuracy test results from outputs from different LLMs.
Comparison of AO and COT
In the investigation of the prediction methods of LLMS, the researchers had paid special attention to the effects of immediate variations in the preservation of the desired answers. In order to achieve an in -depth understanding of the phenomenon, we have selected several models that had shown an excellent performance in various teams to test them using the thinking chain (COT) approach. Afterwards we only compared COT's accuracy rates with those of the answer (AO). By calculating the difference of the middle accuracy rates between the two response methods, we visually demonstrated the discrepancy of the results and used hypothesent tests for objective statistical validation.
The difference in the initial accuracy rates between cot (thought chain) and AO (only answer) was shown in Figure 10. Among the 5 LLMS tested LLMS exceeded AO in 4. In order to examine the results across different domains, Cot AO only exceeds in 5 out of a total of 20 sub -tests. It has been indicated that the use of the COT response method AO is not necessarily superior, which in contrast to the widespread conviction is that cot could be more precise than AO.
Otherwise it was also found that the different answer methods had actually influenced the LLM outputs. The difference in the middle accuracy rates between the two response methods was determined at less than 3%. However, it was unclear whether this influence is positive or negative. In order to further check this phenomenon, we assumed that there was no significant difference in the accuracy rates of LLMS during the evaluation during the evaluation during the evaluation. Paired rehearsal t-tests were carried out on the test data with a P-value threshold of 0.05. The test results showed that in most cases there was no statistically significant difference between the results between cot and AO response methods.
During the experimental procedure, a fascinating observation was found that the models needed significantly more time compared to the AO method to react with the COT approach. Especially in the case of the QWEN1.5-14b chat model, the average response time for AO was recorded with 2.38 seconds per question, while the cot method expanded to 62.23 seconds per question. The revelation underlined the importance of the inclusion of the response time as a critical metric in addition to accuracy when evaluating the efficiency of LLMS.
This study recognizes the existing challenges in the compensation of the argumentation path and calculation efficiency within the current COT methods. Recent studies have shown that the tightening of cot processes through approaches such as dynamic pruning of redundant argumentation steps (COT-Influx) can be demonstrated (COT-Influx)21 and the implementation of iterative optimization preference mechanisms22. Building on this advances, our future work will concentrate on the development of strategies for easy argumentation paths for COT and aim to improve the comprehensive performance in practical applications and at the same time maintain calculation efficiency.
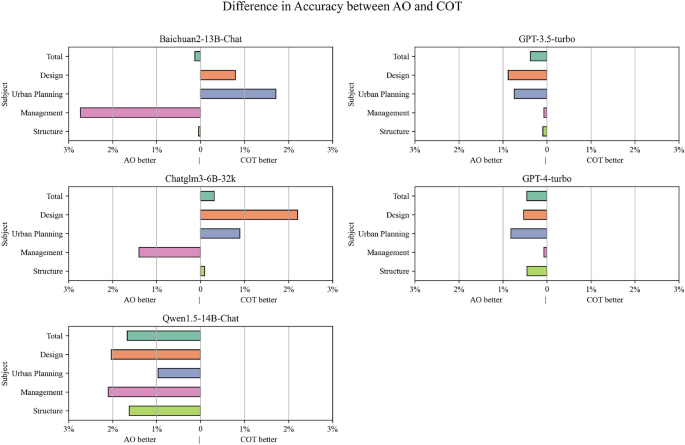
Difference in the initial accuracy rates between AO and COT for certain LLMs.
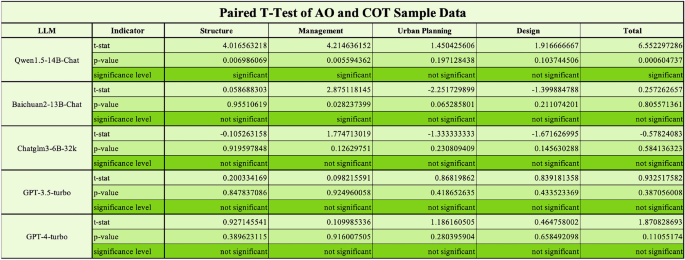
T-Test results for AO and COT.